


More than o1 way to do it
Hmmm......

OpenAI is working on ways to make LLMs cure cancer. I’ll never quite know what the correct reaction to news like this should be, but presumably it triangulates between excitement, disbelief, and concern.
Certainly, that age is not yet upon us. But the company claims to be heading in that direction with its newest product, o11 – a large language model trained to “think before it answers”.
The headline results are certainly impressive: the new model ranks in the 89th percentile on competitive programming questions, and would count among the top 500 maths students in the US. Even more interesting is how this progress has been achieved: OpenAI claim to have found a way to make the next-word prediction machines we all know and love reason.
It’s worth taking a step back and ask what this means, the degree to which its true, and what the new paradigm implies for our scrambling attempts to use, govern and co-exist with these alien intelligences.
How did they do it?
The details of exactly how this progress has been achieved remain arcane for now. But a plausible high-level explanation can be pieced together from combining OpenAI’s public comments with the things we already know about LLMs and their constraints.
Let’s start with what we know about LLMs. It’s difficult to find language to describe the kind of intelligence that LLMs possess, but a simple way is to characterise them as deep heuristic machines. Because they are above all trained to predict plausible continuations of text, they excel at any question for which “looks like a plausible answer that could be correct” is the criterion.2 This gives us a crude way to understand how the size of a model corresponds to performance – the larger and more capable a model, the deeper these heuristics become.3 In other words, LLMs possess “incredible intuition but limited intelligence”.
We’ve also known for a while that the best way to bootstrap these intuition machines into intelligent ones is to get them to tackle problems step-by-step, reasoning “out loud” with natural language, rather than jumping straight to an answer. Here’s a simple example of how well this works in a much earlier, more primitive model:
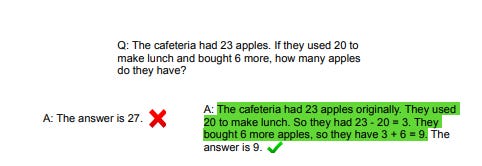
This phenomena, dubbed “chain of thought”, seems to work by giving models the chance to break down problems into smaller chunks and solve them (proto-)systematically, much like a human would. In short, it gives LLMs the chance to simulate System-2 thinking in digestible System-1 steps.
And though it helped, chain of thought remained beset with persistent problems. It’s not entirely easy to explain why – our understanding of why and when LLM reasoning fails remains stubbornly imperfect, but one thing we can say for sure: they suck at recovering from errors. In a sense this is unsurprising. These are models are trained to guess how existing text should be continued. This means that they’re almost inherently bad at self-correction — an LLM that starts down an incorrect path of reasoning will often struggle to recognise the error and start over.
This deficiency makes LLMs particularly bad at problems that involve iterating over multiple candidate solutions, checking their plausibility, and going back to attempt alternatives. Thus, LLMs all suck at Wordle. But such iterative problems belong to precisely that “cure cancer”-class of questions that we would love AI to answer some day.
This limitation is one reason why LLM performance quickly plateaus with time. For several tasks, after a certain early point, LLMs do not get better with more time, unlike humans. The Chain of Thought an LLM produces is “locked in”: more time just means more time pursuing the same wrong path. This also partially accounts for how we end up with graphs like this:

The proportion of difficult tasks completed by a human generally increases with time. As humans are given more time, they tend to solve more problems. This is at least partly because humans are able to use extra time to try out a variety of approaches to a problem, recognise mistakes in their reasoning, and correct accordingly. LLMs, on the other hand, show a much earlier and more pronounced plateau in performance. An LLM is more likely to pursue incorrect pathways ad infinitum. It doesn’t matter how long we set it to work – it won’t be curing cancer.
Enter o1. If you read the examples of o1’s reasoning OpenAI have graciously provided us with, one thing in particular will stick out to you: the model has learned to correct itself. It deliberates, it changes its mind – it even says “Hmmm…” as it reassess its strategy.
In the below example, the model is asked to solve a cipher.

Take half a minute to think about how you might solve it – it’s certainly not easy.
No, actually re-read it and experience concentration first-hand for a second.
Once you’ve done that, here’s the solution: pair off letters from the encoded message, convert each to its numerical position in the alphabet (A=1, B=2), sum each pair, then divide by two. This average is then converted back to a letter. For example: (o+y)/2 = (15+25)/2 = 20 = T. This gives us the message “There are three Rs in Strawberry”.
It’s a fairly tough problem that requires you to experiment with a bunch of different solutions and see if any of them hold. GPT-4o eventually just gives up and asks the user for more information. o1 is more confident, and does what any of us would do: start throwing stuff at the wall to see what sticks. It’s first step is to “Try and find a mapping from letters to letters”: basically, write them down next to each other to see if any of the letters in the cipher match the decoded solution. You can see the exact minute it realises this approach is unpromising:

Similarly, you can identify the exact moment the model makes a key observation towards solving the problem:

Reading these transcripts should inspire you with some level of awe. It’s the most I’ve ever come to truly “feeling the AGI”: much more than GPT ever has, o1’s outputs really seem to attest to a human-like form of reasoning. What’s particular funny is the role that key words seem to play in enabling/forcing the model to consider different solutions – it’s impossible to encounter o1 deploying a critical “Wait a minute”, a series of “Alternatively,”’s or a decisive “That seems promising” without feeling that this an intelligence actively searching a wide space of possibilities in the space of natural reason.
How was this remarkable feat achieved?
From what we can tell, OpenAI have trained o1 to use Chain-of-Thought better. The company’s public announcements tell us that they’ve used reinforcement learning to train a model to “think productively”. It remains deeply unclear what this means. The best hypothesis I’ve read is that a trained LLM (good at next-word prediction) is subjected to a further bout of training in which it attempts to solve reasoning problems with a variety of competing candidate chains-of-thought. Correct reasoning paths are rewarded. Do this thousands of times, it seems, and the model slowly starts to learn more general strategies like “intermittently output the word Hmmm, then use that as a prompt to re-read everything you’ve written so far to assess if you’re headed in the right direction”.
It’s not clear what o1 is doing when we prompt it live (that is, during “test-time”). I’ve seen numerous suggestions that the model is creating many candidate chains-of-thought and selecting the most promising candidates according to general principles learned during this training (for more detail, I’d really recommend this post in full). But at least one OpenAI employee has repeatedly suggested that the examples released by the company are in fact complete, which is somewhat at odds with the extraordinarily high per-token cost of the model. This remains a mystery for now.
o1 small step for man
The important take-away, however, is as follows:
OpenAI have made a model that no longer gets stuck. The more time you give it, the more likely it is to solve a problem. Until now, the main way to improve the performance of an LLM was to spend more money on creating it through larger and larger training runs. If you take nothing else from the launch of o1, remember this: we now have LLMs whose performance scales with the amount of time we give them to solve a problem.4 This is not to say that o1 can currently cure cancer – we all expect it to feebly plateau on certain tasks eventually. We have yet to meaningfully categorise the class of problems that have now been unlocked by o1’s methods.
What we can say for now is that o1 appears better at problems which require 1) searching over a wider space of solutions and 2) evaluating the viability of these solutions until it finds one that is presentable. The tactical Hmmm…’s it has learned during its days in the RL-trenches appear to make it drastically better than GPT models ever were at both search and evaluation. The more time it gets, the longer it can search and the more scrupulously it can reassess its progress.
Critically, for now, OpenAI have taken the all-important lever controlling how long the model spends on a task out of users hands. No private individual will be launching moonshot o1 cancer drugs in the immediate future. But the firm intend on doing so at some point. When they do, it’ll be time for us all to answer some challenging questions about when and where we do this.
For now, which just have a slightly better model with unclear use cases. This is not the transformative moment. We remain squarely within the “those who find ways to use these models in their everyday become more productive” stage of AGI.
OpenAI have been pretty forward about this, too and readily admit that they are themselves unsure of the use case. A plausible hypothesis is that this early release of the weaker -preview and -mini models is a way of figuring out what the market likes by collecting data on how users use o1.
It’s unclear to me how much of a leap o1 represents towards getting us that all-important drop-in remote worker. On the one hand, solving longer problems and self-correcting are undoubtedly important steps. o1 still hallucinates. We’ve not yet seen o1 solving really really long problems – what will that look like?
Over the coming weeks and months, we’ll want to know the following:
The on-boarding problem: how does o1 handle vast amounts of new information?
To put o1 to task on real-world problems you solve in your job, you might need to provide it with a hell of lot of background information, whether that’s familiarising it with your code- or customer base. How do o1 models fare when reasoning over extraordinarily long contexts? Current LLMs witness a drop-off in the ability to integrate enormous amounts of new information at once: even LLMs with nominally massive context windows that allow them to identify individual sentences in giant corpora of text fail to globally reason over large information that they’ve been fed in-context. This is one reason why I struggle to get LLMs to help me on long writing projects — they tree-to-forest mapping appears fundamentally impaired.
Can you build good agents with o1?
Talking to models on a chat interface is helpful for boosting your own productivity, but the most bullish hopes for AI-transformation depend on the creation of more autonomous systems that can work away at problems over longer periods of time, storing memories, and interfacing directly with the products you want them to create.
We can build rudimentary agents like this already with GPT-like models by giving them simple “scaffolds” that store their memories as natural language, as well as digital hands and feet to interact with their virtual worlds. Does o1 provide new paradigms for agent-creation?
An early suggestive glimpse from the OpenAI system card suggests that scaffolds built for GPT-like models do not translate well to the o1 family, which “seemed to struggle to use tools and respond appropriately to feedback from the environment”. Given some extra time with the model, however, an external evaluator playing with o1 was eventually able to create scaffolds “better adapted to them” that brought their performance on par with current best performing scaffold GPT-agents. This was achieved in a matter of days – it remains possible that the medium-hanging fruit is a hell of a lot juicier here.
When will we get flexible test-time compute, and how much of a difference will it make?
A lot might hinge on just how much of a difference expanded test-time compute takes. o1 gets a lot better at the International Maths Olympiad when allowed to try out thousands of solutions. In certain environments that give reliable feedback on the success of an experiments, we’d expect the returns on further test-time to be pretty substantial. Much of the impact of o1-like models is therefore likely to hinge on how, when, and to whom OpenAI provide flexible test-time compute to.
Technically, the only product they’ve released right now is o1-preview and o1-mini. These are less capable versions of the real o1 model that they have yet to release to the public. Best guess why is some mix of 1) o1 doesn’t yet meet their safety standards; and 2) they want to use data generated from customer use of the -preview and -mini model to further tweak the OP one for a proper, successful release.
It might be odd for us to think of things like “ability to tell an entire story in English” or “build a website from scratch” as something that can be solved with ‘heuristics’ but I agree with Wolfram that the early conclusion to draw from GPT-3’s success is that the world is in fact computationally shallower than we previously thought. Templates do in fact get you that far once you can use a billion dimensions to build them.
Before o1, we had some ingenious glimmers of ways to convert additional compute time into higher performance. We’ve seen that one problem to solve is that every time an LLM makes a reasoning step during a chain of thought, it is at some small risk of locking in errors that it fails to recover from. A natural workaround is to get an LLM to produces thousands of candidate chains of thought. With a clever way to identifying promising candidates, you’ve already reduced some of the dreaded impact of probability on your outputs. Combine this with a way to improve the promising candidates, and you can seriously improve what LLMs can do.
This led to some bizarre and interesting ways to brute-force LLMs into solving difficult reasoning tasks. The now canonical example is Ryan Greenblatt’s success on the challenging reasoning benchmark ARC-AGI, which presents the exact kind of systematic, iterative problem that LLMs usually struggle with. He achieved this by getting LLMs to generate thousands of solutions to a problem and selecting the best ones.
There is at least two obvious ceiling to the benefits of this approach. One key difficulty with generalising Greenblatt’s approach to other problems – like curing cancer – is that his solution relies heavily on a way to identify promising candidate solutions from the initial thousands (the format of the ARC-AGI task means that you can check your solutions against existing examples). What o1’s RL training gives us is a model which has been trained to do this evaluation itself – its training has given it a way to evaluate what kinds of reasoning pathways seem promising, prompting it to actively search for alternatives. The other ceiling is cost: creating thousands and thousands solutions eventually just runs up your bill. A model trained to do this from the outset will presumably have to cast a less wide, and therefore considerably cheaper net.
This steinhardt post seems relevant still:
https://bounded-regret.ghost.io/what-will-gpt-2030-look-like/amp/